🔬 Why is Confidence Inaccurate in Standard MDLMs?
Key Insight: Since incorrect but visible tokens never receive training gradients, the model has no mechanism to learn that it should express uncertainty about potentially wrong tokens. The confidence values for visible tokens are essentially untrained and meaningless for error detection.
As illustrated in the figure, during MDLM training: the cross-marked boxes ([MASK]) represent masked tokens where the reconstruction loss is applied and gradients flow. The beige tokens are visible inputs that the model conditions on. Critically, the brown output positions (corresponding to unmasked/visible tokens) receive no supervision during training.
This training paradigm creates a fundamental mismatch: when we later attempt to use the model's confidence to identify errors in visible tokens, the confidence values are unreliable because the model was never trained to produce meaningful confidence estimates for non-masked positions.
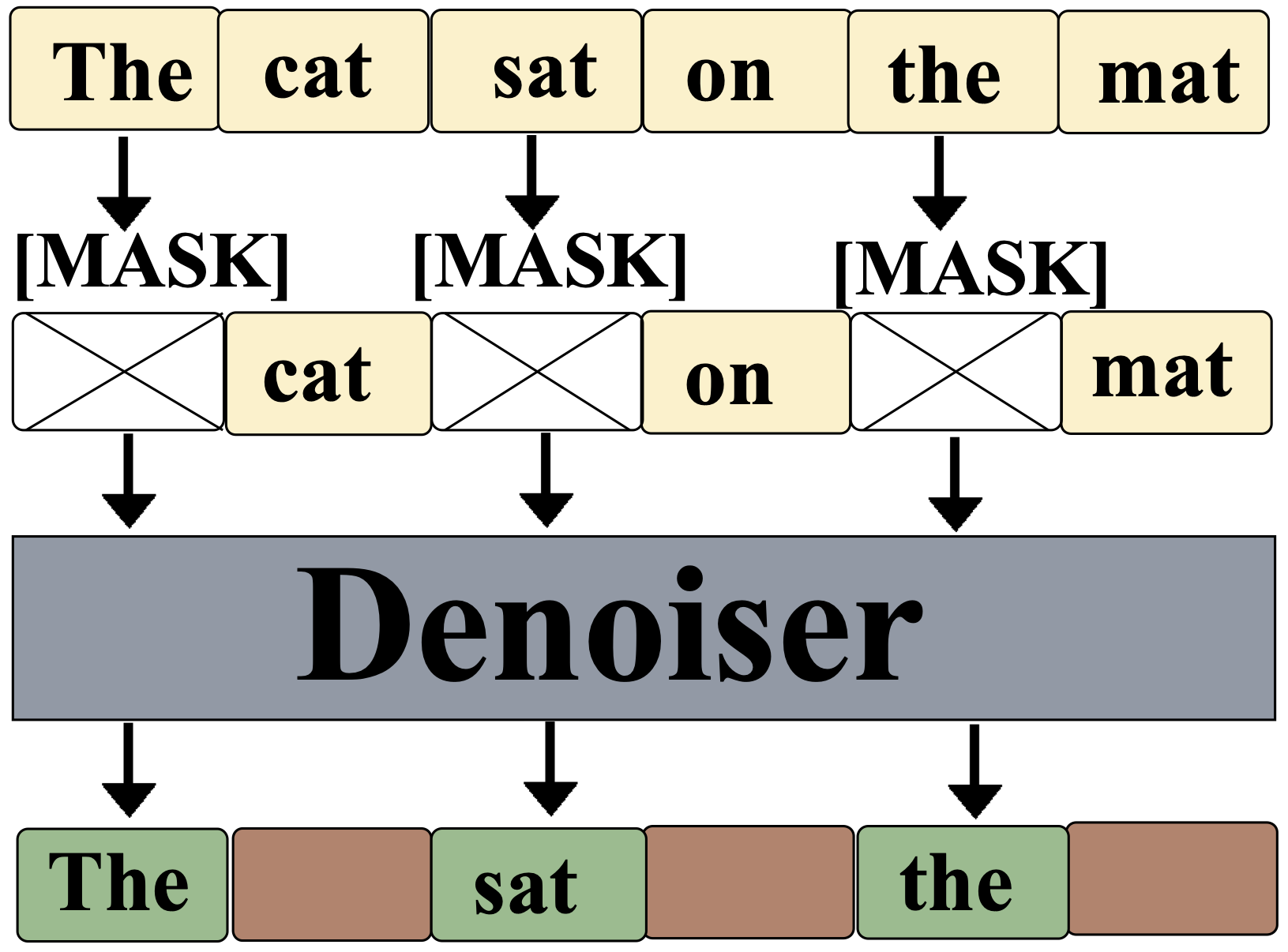
Figure: MDLM training. Cross-marked boxes denote masked tokens, while beige tokens are visible inputs. Green outputs indicate masked positions where the reconstruction loss is applied, whereas brown outputs correspond to unmasked tokens that receive no supervision during training.